About Our Outline
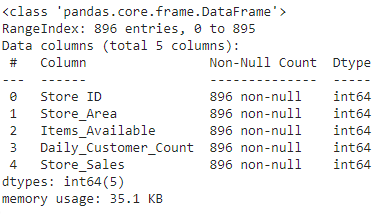
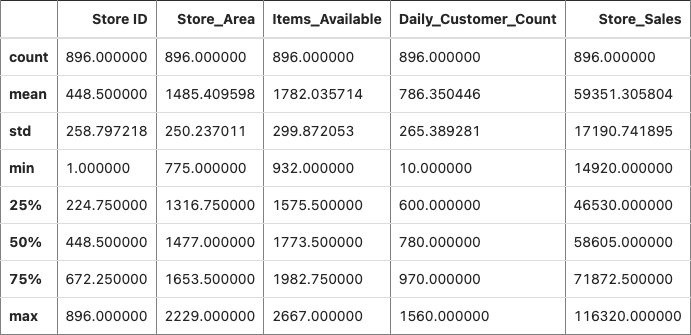
1. We found data from Kaggle, uploaded it to the CoCalc server to collaborate together using Python, imported Python packages, visualized the data, and trained different machine learning models.
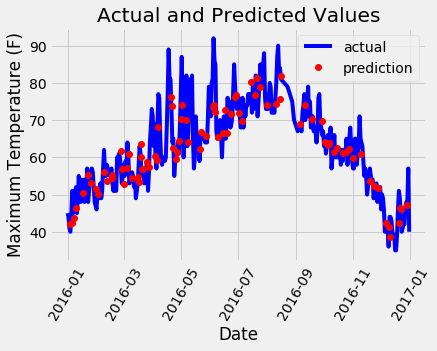
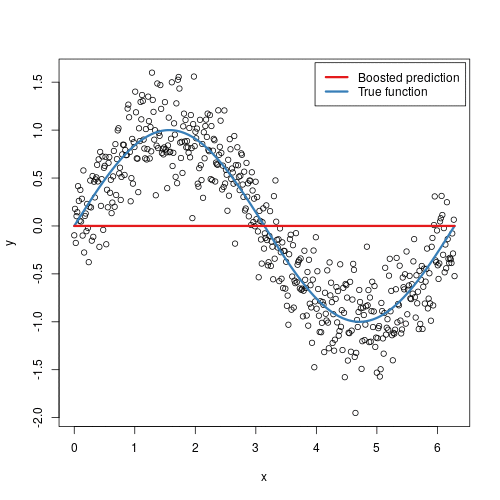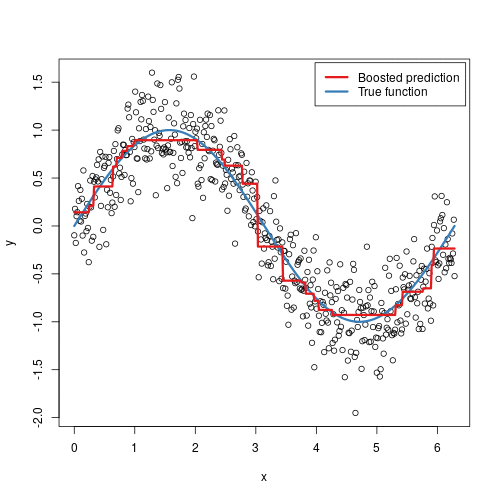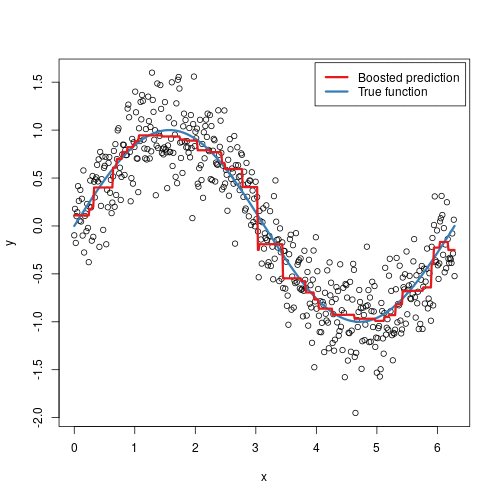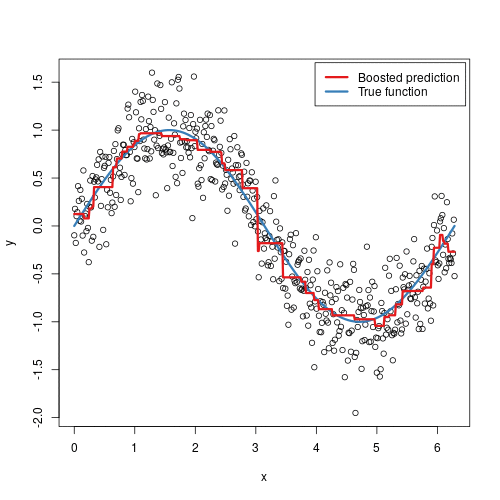
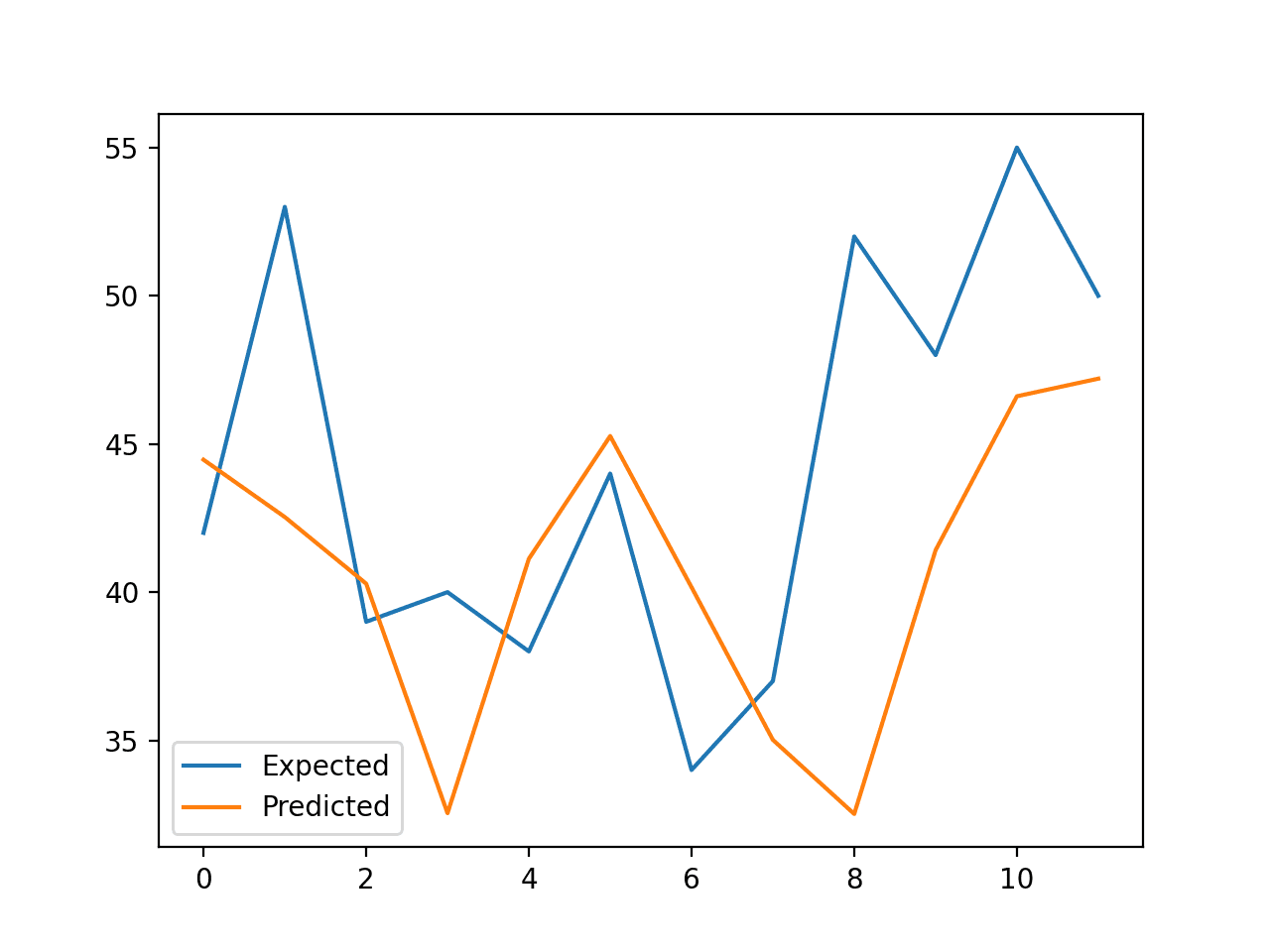
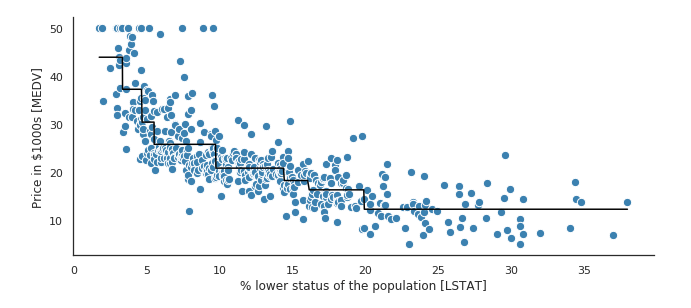
2. We used information about some factors in a supermarket to predict store sales in order to help retail businesses become successful.






}})

}})